Некоторые запросы пользователи вводят в Яндекс почти ежесекундно. Их количество достигает 300 миллионов, в то время как действительно уникальных поисковику задают намного меньше – всего 100 миллионов. Поиск «Палех» помогает Яндексу понять, что ищет человек, он анализирует смысл даже длинного запроса.
Поисковик на основании нейронных сетей выявляет суть запроса и найденного сайта, даже если общих ключевых слов между ними не обнаружено. Он все время накапливает статистику и в итоге с лёгкостью обнаруживает смысловое сходство.
Суть «Палеха»
Чтобы наглядно увидеть, как распределяются все запросы, представим график в виде птицы:
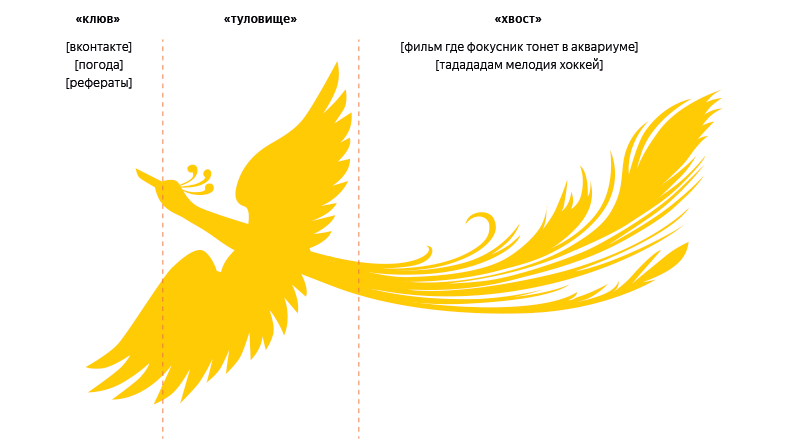
- Самые часто встречающиеся типа «вконтакте» − это клюв;
- Запросы средней частоты составляют тело;
- Уникальные и редкие складываются в хвост птицы.
Алгоритму решили добавить исконно русских особенностей и дали имя «Палех» в честь сказочной Жар-птицы по мотивам палехской миниатюры. Именно он позволяет точно отвечать на все уникальные запросы из хвоста.
К примеру, некоторые люди пытаются узнать название книжки или фильма, описывая один из эпизодов, а маленькие дети еще не поняли, как правильно общаться с поисковиком и в поисковую строку текст вводят в формате общения с живым человеком: «Яндекс, подскажи интересные игры для девочек, где есть единороги».
Такие поисковые фразы поисковику сложнее обрабатывать по сравнению с короткими из птичьего «клюва», которые ищут ежедневно и по ним уже сформировалась статистика. Ситуацию сильно усложняет то, что на подходящей странице суть у релевантной статьи и у запроса одна, а вот выражено это по-разному. Поэтому к решению проблемы привлекли нейронные сети.
Ключевая особенность – работа на основании семантического вектора
Поскольку компьютеру проще обрабатывать числа, нейронную сеть обучили перекодировать все заголовки страниц в Яндексе в числа (в несколько групп из 300 чисел). Теперь поиск сходства между веб-страницей и запросом пользователя проводится по принципу сравнения чисел.
Такой метод обработки называют семантическим вектором, и он как нельзя лучше подходит для поиска результатов из длинного хвоста нашей птицы, статистики для которого еще слишком мало. Вариант с представлением веб-страницы и поискового запроса в трёхсотмерном пространстве позволит находить между ними соответствие, даже если общих слов у них нет.



